 超算云
超算云 AI智算云
AI智算云在北京超算V100-32G顯卡上跑WRF是一種怎樣的體驗?
在北京超算GPU上跑WRF是一種怎
1WRF on GPU?YES!
WRF是在美國國家大氣研究中心(NCAR)開發的天氣研究和預報模型。它被162個國家的36000多個注冊用戶廣泛使用。WRF具有多個動態核心,支持大規模并行計算,且系統可擴展性很強。WRF 適用于從米到數千公里的廣泛應用。它是氣象學科中最為廣泛使用的數值模式之一。
熟悉WRF模式的小伙伴都知道,WRF是在CPU上運行的。而隨著高性能計算技術,特別是使用圖形處理器(GPU)等硬件進行大規模并行計算的技術正在日漸成熟,并在人工智能等領域不斷長足發展。
那么,既然WRF如此適合大規模并行計算,那么,我們可以在GPU上運行WRF,以達到減低成本、增加效率的效果嗎?答案當然是YES。
2AceCast: WRF的GPU版本
AceCast是美國TempoQuest (TQI)公司開發的軟件產品。其前身為英偉達公司支持開發的WRF-G。它由GPU提供支持,可以加速WRF模型。AceCAST 是五年來一絲不茍的研究和開發的產物,它使得 WRF 用戶能夠利用 GPU 硬件與傳統 CPU 計算的高度并行性來保證優化性能。AceCAST 包含了大量重構的通用 WRF 物理、動力學模塊和namelist,它使用了NVIDIA CUDA 或 OpenACC GPU編程技術,允許廣大用戶幾乎不需要改變任何配置,就能將AceCAST作為現有WRF的平替,并加以使用。
GPU通過使用具有高速計算速度和非常高的內存帶寬的多線程、多核處理器來實現異常的加速。通用超級計算、高并行性、高內存帶寬、低成本和緊湊體積的綜合特性使得基于 gpu 的系統成為由普通 CPU 集群組成的大規模并行處理機/計算機系統的一個有吸引力的替代品。基于 GPU 開發的WRF 是目前世界上最快、分辨率最高的天氣預報模型。
TempoQuest 通過利用GPU加速 WRF 模型解決了這個問題。與標準的計算方法相比,AceCAST 是目前世界上最快和分辨率最高的天氣預報模型。通過 AceCAST 運行 WRF,使用戶能夠以更高的分辨率、更低的成本和更深的洞察力運行預測和研究模擬,并加速解決時間流程。AceCAST 的能力為氣象學家和最終用戶提供了 WRF 產品,這些產品能夠提高對全球氣象模型無法識別或在低分辨率情況下無法識別的局部天氣現象的認識。計算性能的提高使得高分辨率的確定性和概率性預報成為可能,而且比在中央處理器上運行 WRF 成本更低,預報模擬加速度一致地將預報處理速度提高了5倍。
3AceCast實戰測試
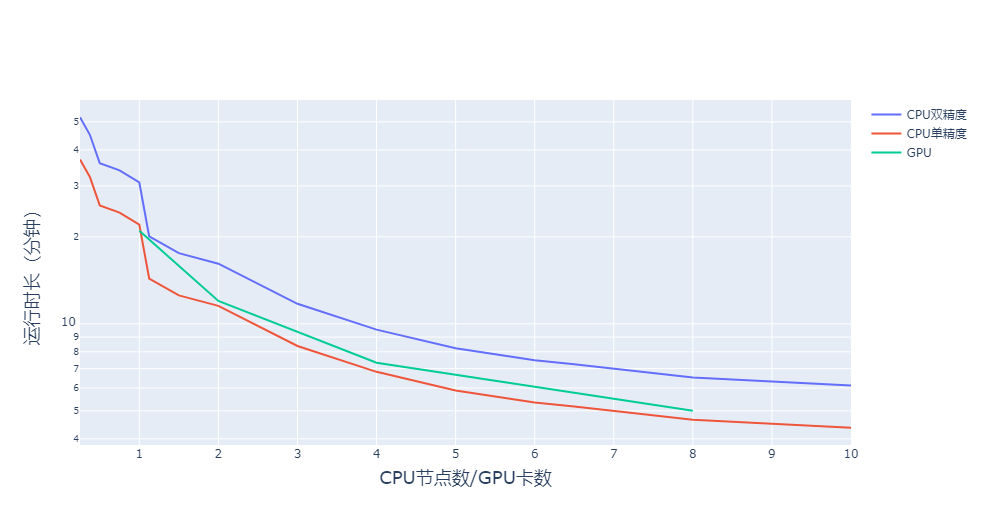
為了準確評估比較WRF在GPU和CPU上的運行速度,我和北京超算團隊一起,使用北京超算提供的8卡V100-32G顯卡資源,對一個800×600×33,單層嵌套的個例進行模擬。分別進行了1卡、2卡、4卡和8卡四個實驗,主要計算其運行效率。實驗結果如下:
GPU個數 | 運行時間 |
1 | 約21分鐘 |
2 | 約12分鐘 |
4 | 約7分20秒 |
8 | 約5分鐘 |
4對比:CPU上運行WRF的效率
CPU節點數 | 運行時間 |
1 | 30分51秒 |
2 | 16分9秒 |
4 | 9分33秒 |
8 | 6分31秒 |
5對比:性能和價格
在北京超算上,一張V100-32G顯卡的價格約為5元/小時(價格根據用戶合同和使用時間等因素不同,會有所波動,下同。);一個CPU核心的價格約為0.1元/小時。由此可以估算出,這次試驗的消費金額(單精度CPU節點以40%提速預計,未進行實地實驗):
設備 | 運行時間 | 理論價格(元) |
CPU*1節點 | 30分51秒 | 3.29 |
CPU*2節點 | 16分9秒 | 3.44 |
CPU*4節點 | 9分33秒 | 4.07 |
CPU*8節點 | 6分31秒 | 5.56 |
單精度CPU*1節點 | 22分2秒 | 2.35 |
單精度CPU*2節點 | 11分32秒 | 2.46 |
單精度CPU*4節點 | 6分49秒 | 2.91 |
單精度CPU*8節點 | 4分39秒 | 3.97 |
GPU*1卡 | 21分鐘 | 1.75 |
GPU*2卡 | 12分鐘 | 2.00 |
GPU*4卡 | 7分20秒 | 2.44 |
GPU*8卡 | 5分鐘 | 3.33 |
6總結與討論
由表格我們可以得出以下結論:
使用單卡GPU的性價比最高,約比CPU上單精度計算便宜25%,比傳統的雙精度便宜50%左右;
就速度而言,在CPU(單精度)使用不超過2個節點時,使用GPU也比CPU要快(不考慮輻射參數化方案的影響的前提下;考慮的話,相信速度提升會更明顯)。考慮到我們一般模擬任務不太會超過800×600×33,可見使用GPU,不管是時間還是金錢成本上,肯定都是優于CPU的;
GPU運行速度隨著卡數的上升,并非是線性提高的。具體如下圖所示:
本次采用的GPU為V100-32G。其單精度浮點運算性能14TFlops;而如果我們采用單精度浮點運算性能更高、價格卻更加便宜的3090顯卡(35.7TFlpos),相信GPU的優勢可以變得更為明顯。
總結一句話:要是WRF規模不太大,直接上單卡3090!性價比最高,最省時間!
7參考文獻
FV3 (2017): www.gfdl.noaa.gov/fv3/fv3-performance
Váňa et al (2017) "Single Precision in Weather Forecasting Models: An
Evaluation with the IFS" Mon. Wea. Rev., Vol. 145, No. 2. (7 December 2016),
pp. 495-502, doi:10.1175/mwr-d-16-0228.
北京超算GPU算力資源
A100V1003090A10T4國產DCU等多種型號;提供云主機、集群、裸金屬云服務等多種算力平臺;支持多機多卡,滿足訓練、推理、科學計算等多計算場景需求。讓GPU算力觸手可及,省事省心,高效專注科研!
掃碼免費領取2000核時或200元卡時計算資源!







